Research
Verifying the Robustness of KNNs against Data-Poisoning Attacks
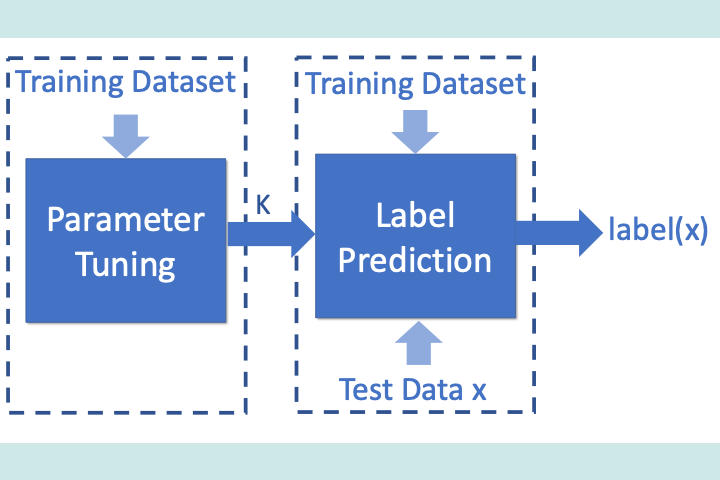
In this work, we present a method for proving data-poisoning robustness of the widely used K-nearest neighbors (KNN) algorithm. Our method can soundly over-approximate the KNN behaviors during both learning (parameter tuning) and prediction phases, while covering all possible scenarios in which up to n training data elements are maliciously injected. We also develop optimizations to prune the search space while maintaining accuracy.
Our empirical evaluation shows that our method is able to prove data-poisoning robustness of KNNs generated from large datasets with high accuracy, while soundly covering the astronomically-large number of possible scenarios.